
官方网站
https://github.com/facefusion/facefusion
colab部署
https://colab.research.google.com/drive/1ADuM0betJnPHn6l4eI7KiB2nS5CjQUw_
mac电脑部署
https://github.com/ethan202405/facefusion/tree/main
一键安装脚本
facefusion/install_facefusion.sh at main · ethan202405/facefusion (github.com)
批量生产图片脚本
ethan202405/facefusion (github.com)
windows版本部署
AI人脸替换工具V5.5完整包
https://www.123pan.com/s/XxKejv-NcSGA.html
一、win10、win11 V5.5
记得软件所在目录不能有中文,闪退的可以把exe名字改成1
【新用户一键搞定5.5完整版】
链接:https://pan.quark.cn/s/e1dd6b1e43c7
提取码:dnsV
【如果你是4.9-5.4版本,下载这个升级包】
链接:https://pan.quark.cn/s/545f141d32d6
提取码:qzQi
——————————————————————
二、mac苹果电脑版V4.2(不过mac的更新不及时,不建议)
夸克网盘:https://pan.quark.cn/s/dfb054f98a13 提取码:yEfK
记得软件安装目录不能有中文
使用指南
大功能选择
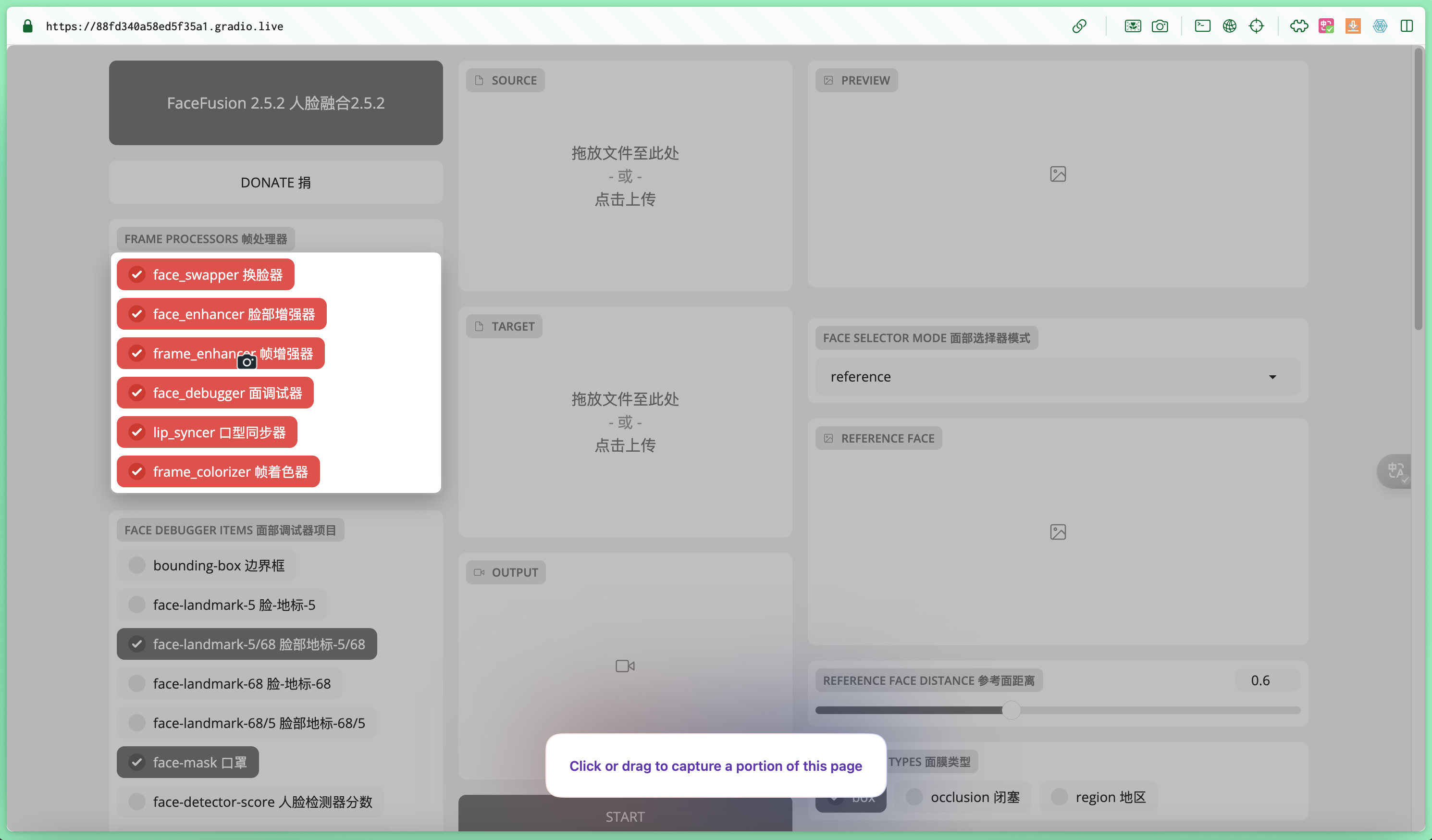
| 几大功能 | 功能 | 适应场景 |
| face_swapper | 换脸模式,这是必选项。 | 人脸替换 |
| face_enhancer | 换脸时提升图像中人脸的质量和清晰度。 | 人脸增强——如锐化、去噪点、色彩校正等来改善脸部细节,让每张脸都清晰如初,魅力四射。 |
| frame_enhancer | 全局提升,每一帧都精致到位。 | 背景增强 |
| 帧着色器 (frame_colorizer) | 为黑白或低色彩素材添加色彩。这些模型利用深度学习技术生成逼真且美观的着色效果,让图像更加生动。 | 图片上色 |
| 口型同步器 (lip_syncer) | 通过从音频中提取语音特征,优化了口型同步的准确性。这使得视频中的口型与声音同步更加自然,让动漫人物开口说话的效果更真实。理解为一种极简的数字人 | 音频+视频,让视频口型跟音频同步;一种数字人 |
人脸增强模型
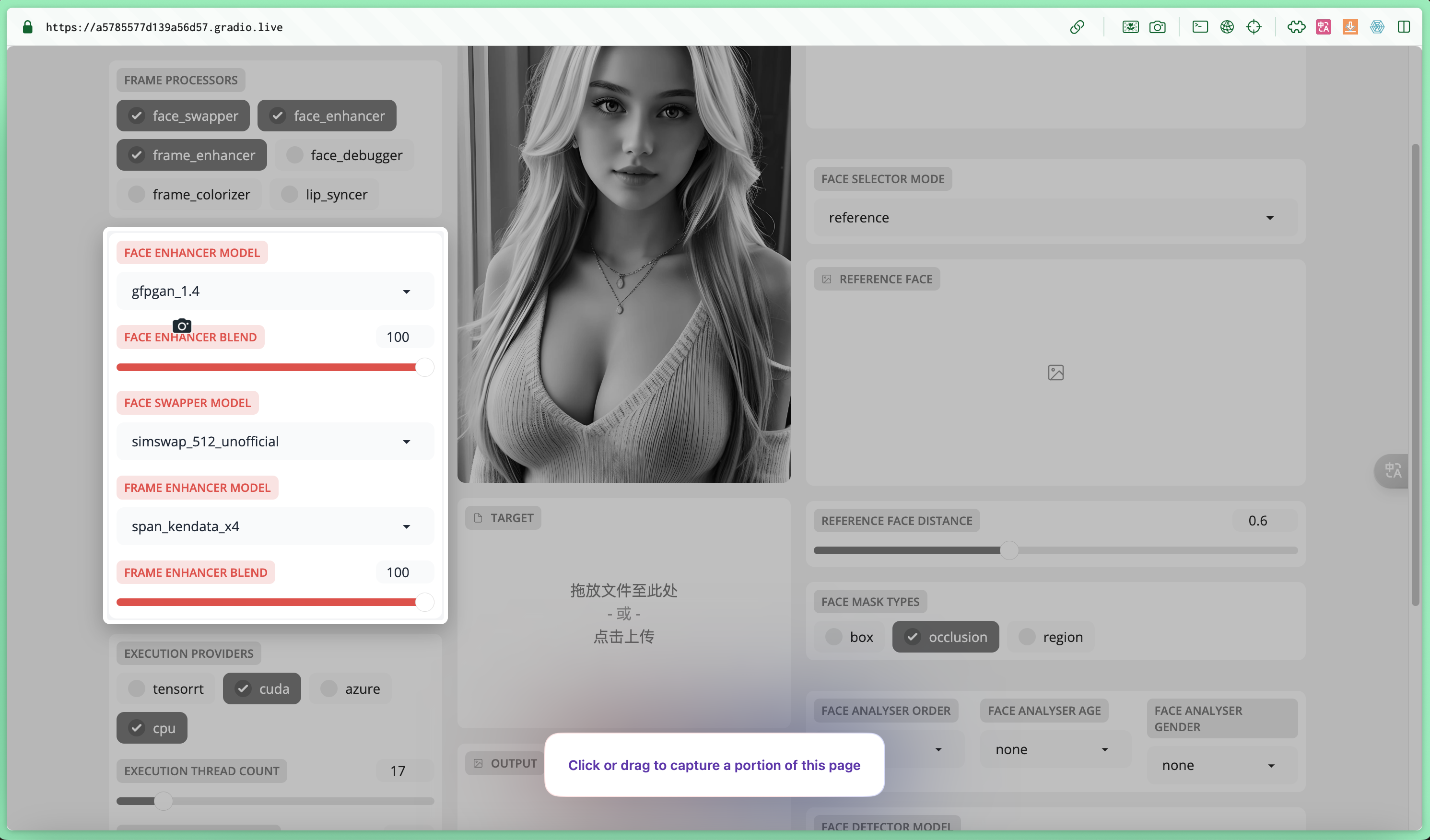
| 几大功能 | 功能 | 适应场景 |
| codeformer | CodeFormer是一个专注于修复和解决人脸图像质量问题的模型,如模糊、噪点和压缩伪影。恢复丢失的面部特征。 | 大幅度提升模糊或受损图像的清晰度 |
| gfpgan_1.2, gfpgan_1.3, gfpgan_1.4 | 不同版本分别代表着算法的迭代和改进。GFPGAN在实际环境下提供适用的人脸修复功能,它通过预训练的GAN模型来修复老照片中的人脸或改进AI生成图像的面部。因此在facefusion多种换脸场合是一个标配的模型。 | 恢复损坏或劣质面部图像 |
| gpen_bfr_256, gpen_bfr_512 | GPEN是一种面部增强网络,它的不同版本支持不同的解析度,如256×256和512×512像素。用于提高人脸的分辨率和图像清晰度。 | 有限分辨率下进行人脸修复 |
| restoreformer_plus_plus | RestoreFormer是一个面部恢复模型,致力于使用深度学习和复原转换技术,修复并增强人像图像,尤其是在有损坏。 | 恢复因压缩而失真的人脸图像 |
上色模型
| 模型名称 | 功能简述 | 适应场景 |
|---|---|---|
| DDColor | 自动学习并上色,减少错误涂抹 | 老式黑白家庭照片或历史档案照片 |
| DeOldify | 黑白转彩色,使照片更现代 | 历史照片修复、电影复原 |
| DeOldify Artistic | 添加艺术效果,增强创意表现 | 艺术家、设计师、摄影师的黑白图像 |
| DeOldify Stable | 稳定上色,提供可靠结果 | 普通用户、历史爱好者的家庭照片修复 |
| DDColor Artistic | 艺术化着色,审美价值高 | 艺术创作与教育,老旧艺术品的数字化复原 |
运行硬件
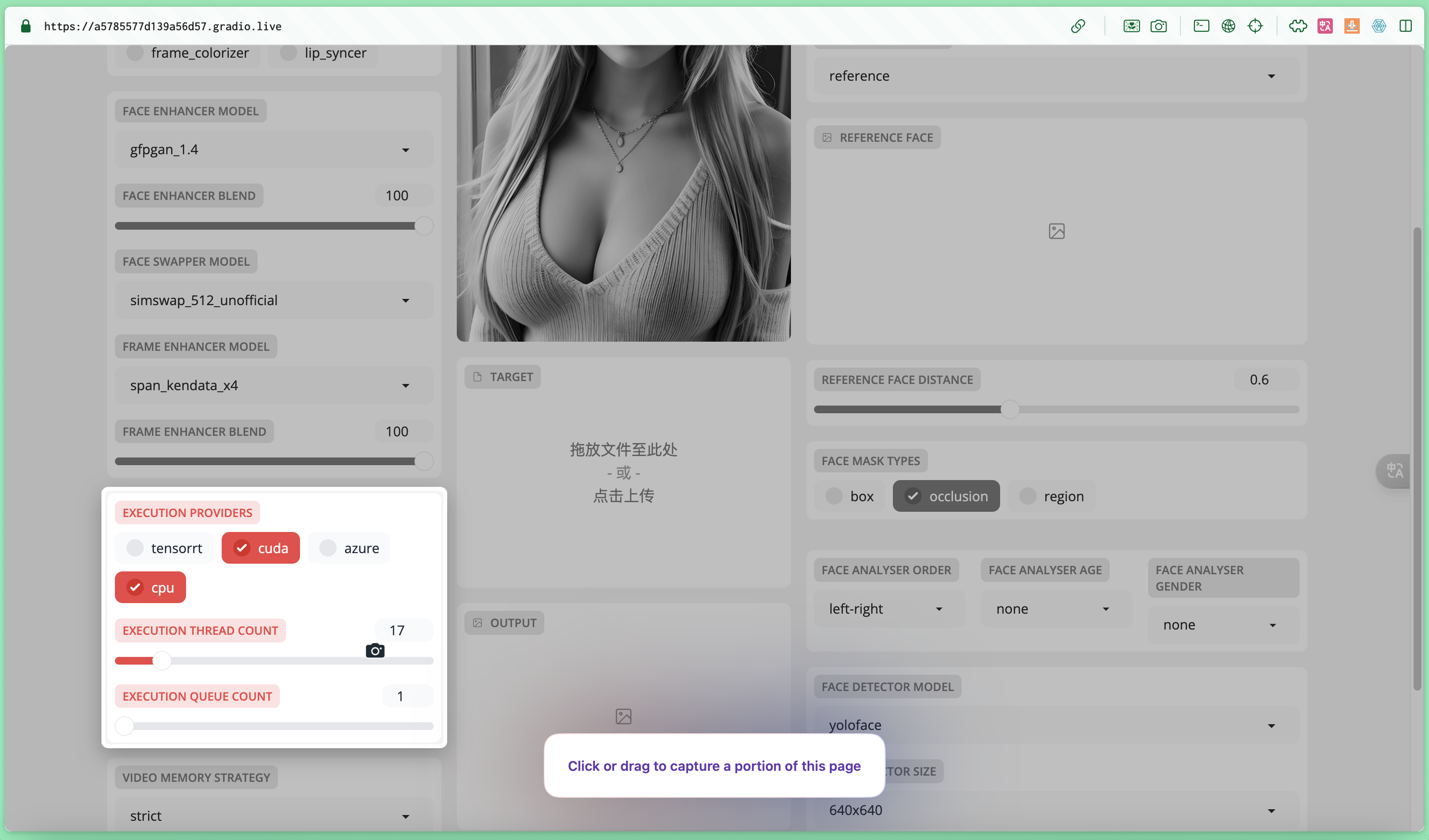
| 几大功能 | 功能 | 适应场景 |
| CPU选项 | A卡和集成显卡的必选项。缺点换脸速度慢。 | mac电脑,无英伟达显卡的 |
| cuda | 英伟达显卡,速度就是快 | windows+英伟达显卡 |
| EXECUTION THREAD COUNT | 设置换脸时的最大线程数,在显卡有8G以上显存可以适当调高该值,以加快换脸的运算速度。 | 通常是显卡的1.5倍,mac电脑的显卡,采用的是跟内存一致的资源 |
| EXECUTION QUEUE COUNT: | 批量换脸时才用 |
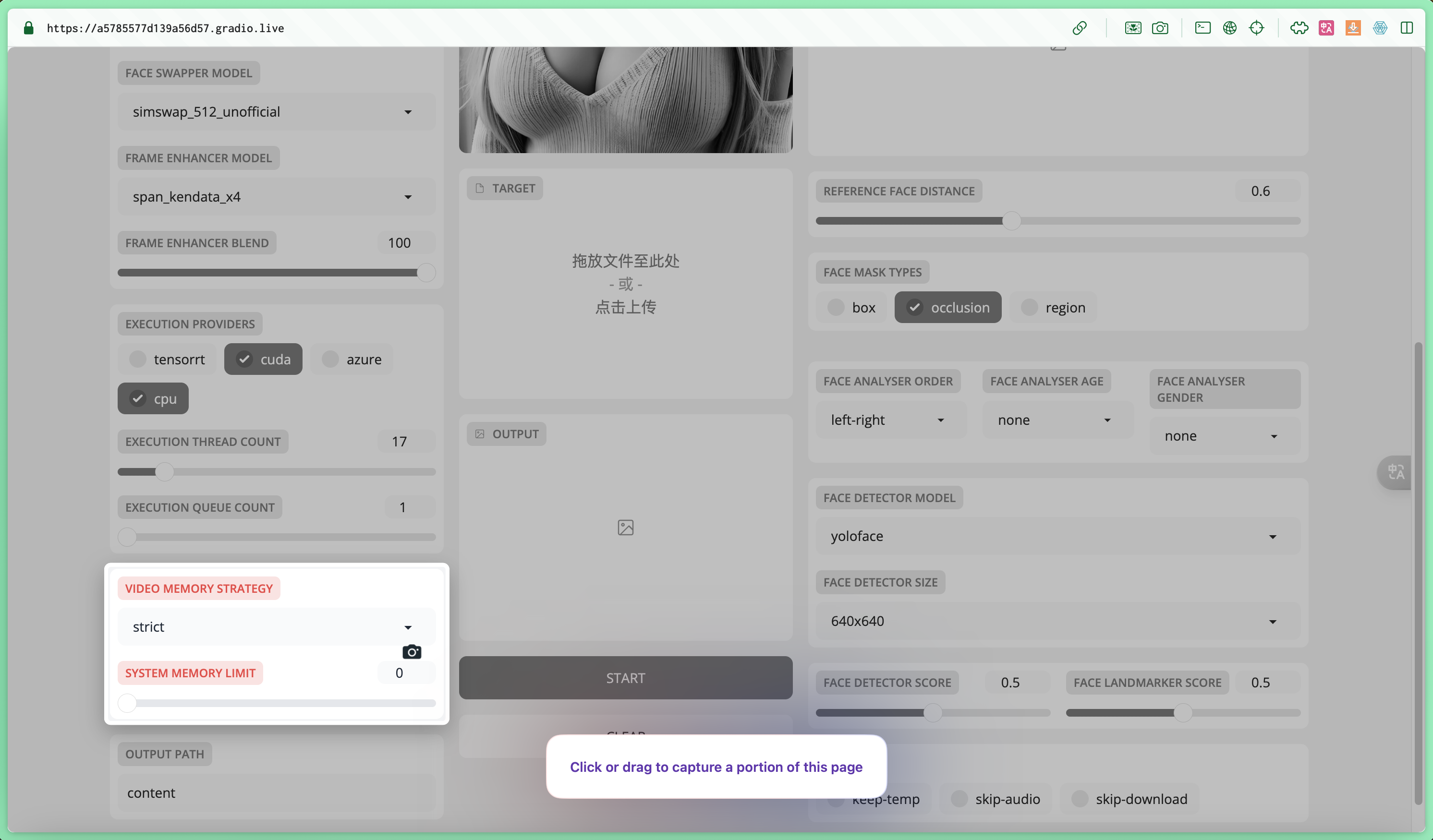
VIDEO MEMORY STRATEGY(显存占用策略)
Strict(严格):在执行时会严格限制显存使用(默认选项),适用于显存资源较为有限的系统环境。
• Moderate(适中): 在适中模式下,会更灵活地使用显存。
• Tolerant(宽容): 宽容模式下,在处理大型或复杂任务时使用更多的显存,而不是在使用量上设定太多限制,适合显存资源充足的硬件设备。
SYSTEM MEMORY LIMIT内存限制:该选项限定facefusion在系统内存中的最大占用量。
TEMP FRAME FORMAT:过程中要单独处理每一帧的图片。
- JPG格式(默认选项)的图片通常文件小,保存快,但是图片的细节可能会有一点点损失;
- PNG格式文件稍微大一点,处理可能慢一些,但保存的图片质量会更好一些。
所以具体还是看自身需求,追求效率选择jpg比较适合。更在意视频质量,那么选择png、bmp格式更合适。
| 功能 | 说明 | |
| libx264 | 在图像质量和文件大小之间平衡选项,是facefusion默认选项。 | |
| libx265 | 提供了比H.264更高效的压缩,在保持同等视频质量的同时减少了文件大小。 | |
| libvpx-vp9 | 非常好的压缩比,非常适合Web视频流传输。 |
OUTPUT VIDEO PRESET
简单来说,选项从ultrafast到veryslow是一个从速度优先到质量优先的过渡性选项。越往后,编码时间越长,但文件压缩效果越好,理论上质量越高。
- 如果你需要快速编码(不再意图像质量),可以选择
veryfast或faster(默认选项)。 - 如果对视频质量有较高要求且不介意较长的编码时间,可以选择
slow、slower或veryslow。
OUTPUT VIDEO QUALITY
压缩质量。设置值范围通常是从80到100
OUTPUT VIDEO FPS
默认值是30fps(每秒30帧),最大值可以设置到60fps(每秒60帧)。
FACE SELECTOR MODE(面部选择器模式)
| many | 想要在视频中替换多个人的面部 | |
| one | 只想替换视频中的一个特定人物的面部 | |
| reference | 提供了一种更灵活的面部选择方法,可以根据参考图像或简单匹配来确定要替换的面部 |
识别之后的人脸
reference-face-distance
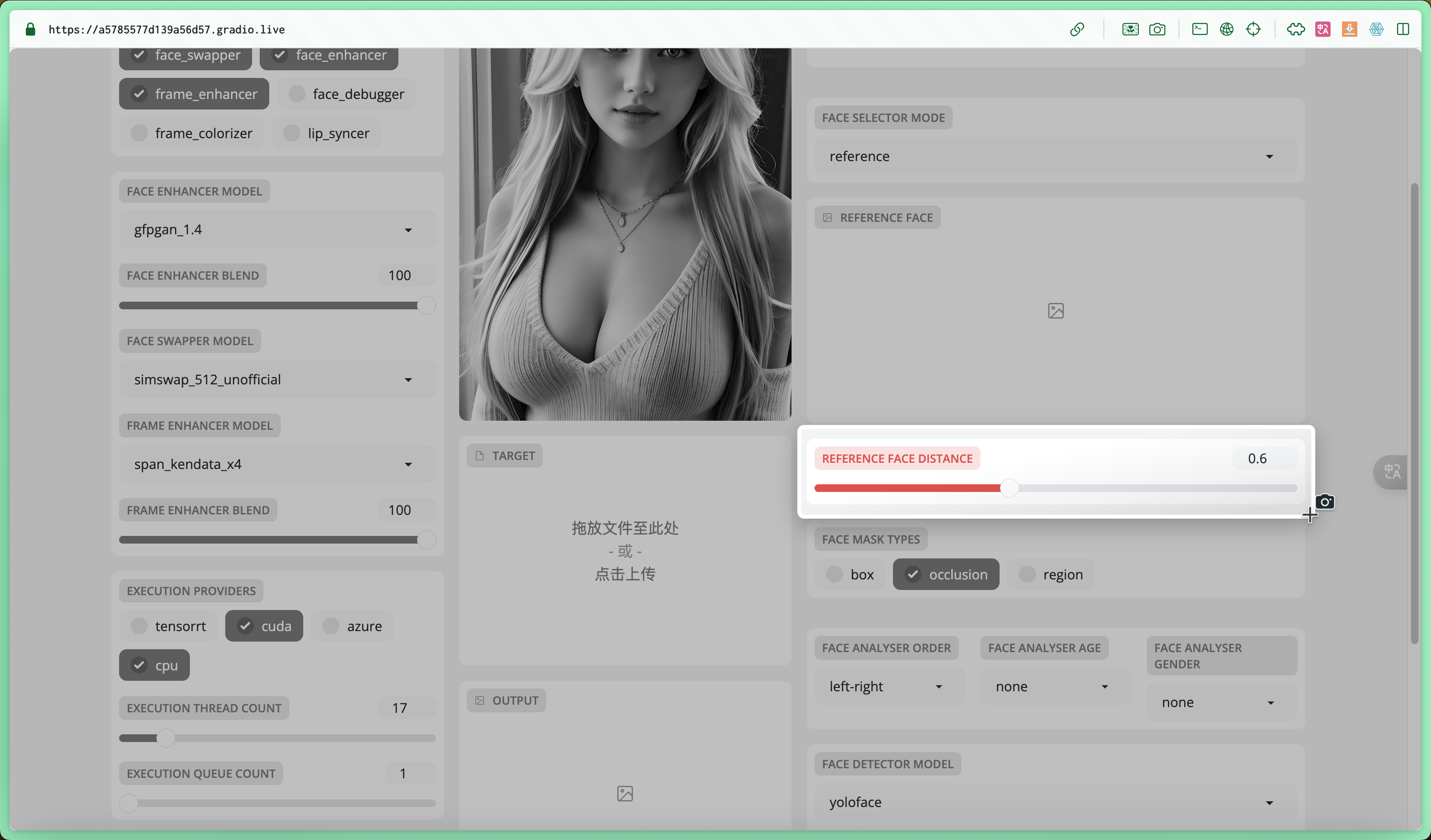
此参数用于指定参考面部与目标面部之间所需的相似度。它的默认值是0.6,范围从0到1.5 ;越大越相似
遮罩方式
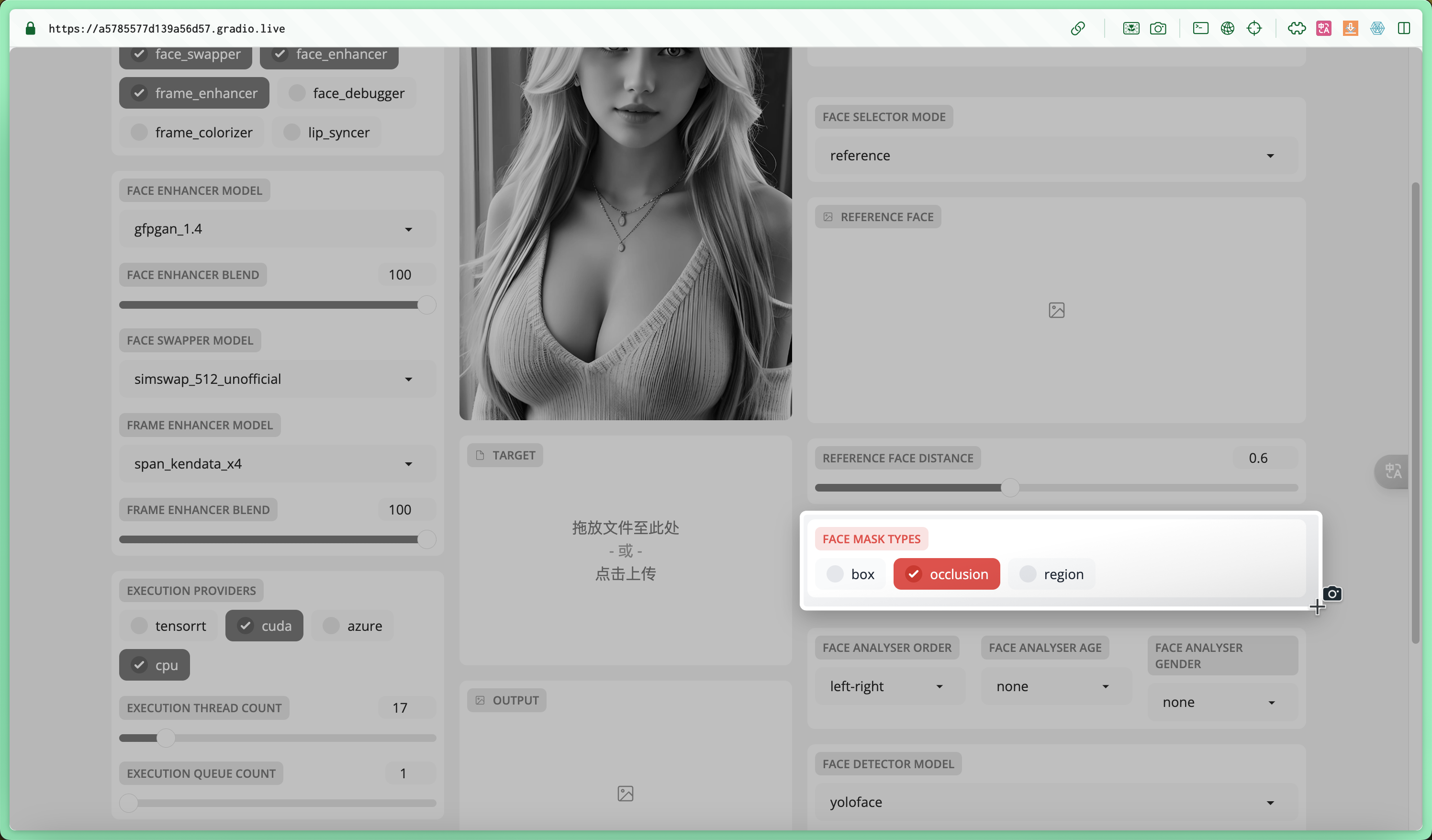
| 类型 | 说明 | 适应场景 |
| Box | 快速简单 | 适合初学者 |
| Occlusion(遮挡) | 精准识别,即使面部被遮挡也能精确替换。 | 比如被眼镜、手指、帽子等挡住脸了 |
| Region(区域) | 最精细的遮罩类型,选择特定面部特征进行定制替换。 | 如皮肤、左眉毛、右眉毛、左眼、右眼、眼镜、鼻子、嘴巴等进行遮罩。 以达到对面部的某部特殊处理,比如仅替换嘴巴、眼睛部分,而不改变整个面部,使得换脸效果在精度和自然度上更进一步 |
FACE MASK PADDING
参数允许您对面部遮罩的四个边界(上、下、左、右)添加额外的空间,以便更好地控制面部替换的区域。
FACE DETECTOR MODEL(面部检测模型)
| 说明 | 功能 | 适应场景 |
| yoloface | 检测模型,适用于快速且实时的面部检测 | 默认 |
| retinaface | 这个模型在面部检测的精确度上表现更好 | 特别是在处理小脸或在复杂背景中的脸部时 |
| scrfd | 高效的面部检测模型 | 能够在各种尺寸和姿态的脸部上实现准确检测 |
| yunet | 轻量级的模型 | 适合在资源有限的设备上使用,低配电脑 |
FACE DETECTOR SCORE 和 FACE LANDMARKER SCORE
在FaceFusion中的使用场景主要涉及到提高面部检测和特征点定位的准确性,两个参数对于提高换脸效果的自然度和准确性至关重要。
其他
| –skip-audio | 跳过音频处理,在处理视频时跳过音频轨道的处理 | |
|---|---|---|
| –skip-download | 跳过下载步骤。 | |
| keep-temp | 是否保留临时文件 | 执行后不会删除临时目录文件 |
评论(0)